The Promise The Practice and The Paper Review
Symbolic regression is one of those machine learning tasks that we really wish we were good at, but alas, it is a no-go.
Introduction and Motivating Examples
In a nutshell, the goal is to find the ‘simplest’ mathematical formula that fits a data set.
Suppose we had the data 




Compare this to linear regression in which we fit a linear model to the data or generalizations of linear regression. In a way, symbolic regression is about providing the alphabet letters in the form of symbols and finding the best word to fit our data. Linear regression is about pretending everything is linear, and all errors are normal. So why isn’t symbolic regression more widely used, or at least a more active research topic?
Suppose we had the following python code.
import numpy as np
X = np.random.random((30,5))
y = np.asarray([np.dot(x,x) for x in X])
We see the process that generates ![y[0] = X[0]^T \cdot X[0]](https://s0.wp.com/latex.php?latex=y%5B0%5D+%3D+X%5B0%5D%5ET+%5Ccdot++X%5B0%5D&bg=ffffff&fg=111111&s=0&c=20201002)

Okay, so maybe we should just include more symbols if this formula looks too complicated. To see why this is a problem, it helps to visualize searching for a symbolic formula as that of looking through a tree.
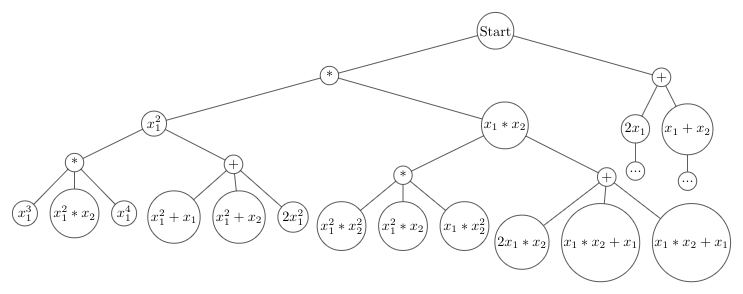
For this tree, let us assume we have only two symbols, multiplication (*) or addition(+). We first choose either addition or multiplication, then we choose which variables to act on. At the start, we only have two variables 
Let us reevaluate our example but add in our new dot product operation. To demonstrate some of the issues here, we are going to add in two other variables 



The Implicit Relaxation Technique
Classically, the way to solve symbolic regression problems was to use evolutionary algorithms. We just use derivative-free optimization, Eureqa! But we live in the age of AI, and those really fancy Neural Network thingies, can’t we do better? One can think of playing chess as a tree search problem as well.
Solving that tree search problem using neural networks is exactly what ‘Deep symbolic regression: Recovering mathematical expressions from data via risk-seeking policy gradients‘ does. But before going into the details of the paper, let’s take two steps back and one forward.
One of the nice things about reinforcement learning (RL) is its compatibility with derivative-free problems. This compatibility is found in the way RL uses rewards. In a classical deep neural network classification problem, one has a loss function that measures how good our classifier is. We then use an automatic differentiation package to compute a gradient relative to our model parameters and minimize our loss function. Vaguely speaking, an RL problem can be thought of as a game of chance where we want to learn a strategy that wins more than it loses. In an RL setting, we replace our loss function with some reward that tells us if we won or lost and how much. We then show our RL algorithm this numerical reward without providing information on the function that generated it. Our algorithm tries to change our strategy, so we win more on average.
Thus for a particular optimization perspective, we have replaced our symbolic regression problem with a relaxation, finding a strategy to ‘win’ at our symbolic regression game more frequently. If we took a loss-based method, we would need to ensure we could compute gradients in terms of our model parameters and our loss function. However, we want to be able to fit expressions such as 
Down to the technical Details
Note this section assumes some background in math/RNNs/RL to understand fully but should be 90% comprehensible without said background.
The paper provides a few new ideas and some standard ones from AutoML. First, they use an RNN to generate an autoregressive symbolic expression, or 



The local context trick is new to me, but the other aspects of their RNN process are pretty typical in many AutoML domains. I have definitely seen the same techniques in automatic architecture search for DNNs. I also like that the constants are fitted afterward, which dramatically reduces the complexity of the expression generation task for our RNN.
Next, let’s dig into the fun math! The paper, for the sake of comparing results to other methods, adopts a standard unsquashed reward function called “normalized root-mean-square error’ (NRMSE).

Thus our reward is a modification of mean square error with the notable twist of using the standard deviation 



![[1/2, 1]](https://s0.wp.com/latex.php?latex=%5B1%2F2%2C+1%5D&bg=ffffff&fg=111111&s=0&c=20201002)

![[1/4, 1/2]](https://s0.wp.com/latex.php?latex=%5B1%2F4%2C+1%2F2%5D&bg=ffffff&fg=111111&s=0&c=20201002)
This second part is a modification to the REINFORCE policy gradient algorithm for RL to increase risk-seeking behavior, which is a weird anthropomorphic way of describing an algorithm that optimizes top quantile behavior instead of mean behavior.
Let us give a short mathematical overview of REINFORCE and then the result. Let 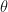


![J(\theta) = \mathbb{E}_{\tau \sim p(\tau|\theta)}[R(\tau)]](https://s0.wp.com/latex.php?latex=J%28%5Ctheta%29+%3D+%5Cmathbb%7BE%7D_%7B%5Ctau+%5Csim+p%28%5Ctau%7C%5Ctheta%29%7D%5BR%28%5Ctau%29%5D&bg=ffffff&fg=111111&s=0&c=20201002)
![\nabla_{\theta} J(\theta) = \nabla_{\theta}\mathbb{E}_{\tau \sim p(\tau | \theta)} [R(\tau)]](https://s0.wp.com/latex.php?latex=%5Cnabla_%7B%5Ctheta%7D+J%28%5Ctheta%29+%3D+%5Cnabla_%7B%5Ctheta%7D%5Cmathbb%7BE%7D_%7B%5Ctau+%5Csim+p%28%5Ctau+%7C+%5Ctheta%29%7D+%5BR%28%5Ctau%29%5D+&bg=ffffff&fg=111111&s=0&c=20201002)
![= \mathbb{E}_{\tau \sim p(\tau | \theta)} [R(\tau) \nabla_{\theta} \log p(\tau|\theta)]](https://s0.wp.com/latex.php?latex=%3D+%5Cmathbb%7BE%7D_%7B%5Ctau+%5Csim+p%28%5Ctau+%7C+%5Ctheta%29%7D+%5BR%28%5Ctau%29+%5Cnabla_%7B%5Ctheta%7D+%5Clog+p%28%5Ctau%7C%5Ctheta%29%5D+&bg=ffffff&fg=111111&s=0&c=20201002)
The last expression has the crucial property. By this log trick, we can avoid taking the gradient of the expectation, and we are left with a formula that we can approximate by sampling.

Their new objective function is defined in terms of 

![J(\theta, \epsilon) = \mathbb{E}_{\tau \sim p(\tau | \theta)}[R(\tau) | R(\tau) \geq R{\epsilon}(\theta)]](https://s0.wp.com/latex.php?latex=J%28%5Ctheta%2C+%5Cepsilon%29+%3D+%5Cmathbb%7BE%7D_%7B%5Ctau+%5Csim+p%28%5Ctau+%7C+%5Ctheta%29%7D%5BR%28%5Ctau%29+%7C+R%28%5Ctau%29+%5Cgeq+R%7B%5Cepsilon%7D%28%5Ctheta%29%5D+&bg=ffffff&fg=111111&s=0&c=20201002)
![\nabla_{\theta}J(\theta, \epsilon) \approx \frac{1}{\epsilon N}\sum_{i=1}^N [R(\tau_i) - \tilde R_{\epsilon}(\theta)] \mathbf{1}_{R(\tau_i) \geq \tilde R{\epsilon}(\theta)} \nabla_{\theta} \log p(\tau_i| \theta)](https://s0.wp.com/latex.php?latex=%5Cnabla_%7B%5Ctheta%7DJ%28%5Ctheta%2C+%5Cepsilon%29+%5Capprox+%5Cfrac%7B1%7D%7B%5Cepsilon+N%7D%5Csum_%7Bi%3D1%7D%5EN+%5BR%28%5Ctau_i%29+-+%5Ctilde+R_%7B%5Cepsilon%7D%28%5Ctheta%29%5D+%5Cmathbf%7B1%7D_%7BR%28%5Ctau_i%29+%5Cgeq+%5Ctilde+R%7B%5Cepsilon%7D%28%5Ctheta%29%7D+%5Cnabla_%7B%5Ctheta%7D+%5Clog+p%28%5Ctau_i%7C+%5Ctheta%29&bg=ffffff&fg=111111&s=0&c=20201002)
The point of our final equation is that it approximates our gradient by computable elements. A couple of issues arise from this formulation. First, how bad is the estimate of our quantile, and what effect does that have on training? One can see that their prior squashing of the reward can have some nontrivial interaction with the objective function. Lastly, our batch size for updating now depends on 
Further generalization of this objective type could include an exploration factor on the bottom quantile without changing much about the current loss.
Next time we will look a some of the experiments in detail and run some experiments of our own.
